「データサイエンス講座(統計編)」(かめ@米国データサイエンティストさん)のノートです。一変数の記述統計学がテーマだった 前回 の続きになります。第10回「共分散」から第17回「決定係数」まで、内容は 多変数の記述統計学 となります。
データサイエンス講座(統計編) - 米国データサイエンティストのブログ
今回も前回に引き続き、多変数の統計量をスクラッチ実装していきます。多変数ということで、少し慣れが必要ですが記述の見通しを良くなるので、ベクトルと行列 を使っていきます。
さて今回の個人的ポイントは、NumPyの実装では アダマール積 と ブロードキャスト の組み合わせが有効だということです。ついつい慣れ親しんだ普通の行列積を考えがちですが、実装時には必ずともそれが最適とは限らないのです。→ 「11 相関係数をわかりやすく解説: 相関行列」
かめ@米国データサイエンティストさんの講座のお供に、今回も是非よろしくお願いします!JupyterLabのノートブックは こちら にあります。
10 絶対にわかる共分散
絶対にわかる共分散【統計学入門⑩】 - 米国データサイエンティストのブログ
- 分散共分散行列 (variance-covariance matrix)
numpy.cov(m, y=None, bias=False, ddof=None):mとyは共分散を計算したいデータ(同じ型)、biasは不偏性の指定、更にddofでbiasの指定は上書きされるpandas.DataFrame.cov(ddof=1)
共分散(covariance)
補足: ライブラリのデフォルトに合わせて で割ることにする。
補足(重要!): 変数 の 偏差 を並べたベクトル 、同様に変数 の偏差を並べたベクトル とした時、右側の の部分は、ベクトルの内積 であることに注意しておこう。これが後の分散共分散行列や相関係数の理解に役立つ。
def my_cov(x: np.ndarray, y: np.ndarray) -> np.ndarray:
return np.sum((x - np.mean(x)) * (y - np.mean(y))) / (len(x) - 1)実行例
>>> weight = np.array([42, 46, 53, 56, 58, 61, 62, 63, 65, 67, 73])
>>> height = np.array([138, 150, 152, 163, 164, 167, 165, 182, 180, 180, 183])
>>> my_cov(weight, height)
np.float64(127.54545454545455)分散共分散行列 (variance-covariance matrix)
個の変数 () に対して、変数の(共)分散を成分に持つ 次正方行列
を 分散共分散行列 と呼ぶ。但し は、変数 と変数 の(共)分散とする。 の場合、つまり対角成分は、変数 の分散 である。
ところで、標本サイズが の時、全てのデータを並べた行列を
とする。但し は、 番目の個体の 番目の変数の値を表す。つまり pandas のデータフレームと同じ形式である。
この時、分散共分散行列 は
で計算できる。但し は 次単位行列、 は全成分が からなる 次正方行列である。また、は転置行列。
weight と height の2変数の場合で具体的に見ていこう。X は各変数のデータを列ベクトルとして並べた行列。
>>> X = np.column_stack((weight, height))
>>> X
array([[ 42, 138],
[ 46, 150],
[ 53, 152],
[ 56, 163],
[ 58, 164],
[ 61, 167],
[ 62, 165],
[ 63, 182],
[ 65, 180],
[ 67, 180],
[ 73, 183]])numpy.column_stack — NumPy Manual
の前に、まずは 次の行ベクトル j から始める。
>>> n = X.shape[0]
>>> j = np.ones((1, n))
>>> j
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])は、各変数の平均を並べた行ベクトルになる。
>>> j @ X / n
array([[ 58.72727273, 165.81818182]])
>>> np.mean(weight), np.mean(height)
(np.float64(58.72727272727273), np.float64(165.8181818181818))補足: @ 演算子は、行列同士の掛け算
Python, NumPyで行列の演算(逆行列、行列式、固有値など) | note.nkmk.me
j を 行並べた J
>>> J = np.ones((n, n))
>>> J
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])を掛けると、
>>> J @ X / n
array([[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182],
[ 58.72727273, 165.81818182]])各変数の平均を 行分並べた行列になる。つまり先ほどの から を引いた行列 は、 の成分から各変数の平均を引いた「偏差ベクトル」 を並べた行列になる。
>>> Xc = X - J @ X / n
>>> Xc
array([[-16.72727273, -27.81818182],
[-12.72727273, -15.81818182],
[ -5.72727273, -13.81818182],
[ -2.72727273, -2.81818182],
[ -0.72727273, -1.81818182],
[ 2.27272727, 1.18181818],
[ 3.27272727, -0.81818182],
[ 4.27272727, 16.18181818],
[ 6.27272727, 14.18181818],
[ 8.27272727, 14.18181818],
[ 14.27272727, 17.18181818]])補足: NumPyではブロードキャストが行われるため、実際には行ベクトルjをかけても同じ結果が得られる。実装時には、こちらのほうが効率が良い。
>>> X - j @ X / n
array([[-16.72727273, -27.81818182],
[-12.72727273, -15.81818182],
[ -5.72727273, -13.81818182],
[ -2.72727273, -2.81818182],
[ -0.72727273, -1.81818182],
[ 2.27272727, 1.18181818],
[ 3.27272727, -0.81818182],
[ 4.27272727, 16.18181818],
[ 6.27272727, 14.18181818],
[ 8.27272727, 14.18181818],
[ 14.27272727, 17.18181818]])従って は偏差ベクトルの内積を並べた行列になる。
先ほど共分散で述べた通り、偏差ベクトルの内積から を割ると共分散になるので、
になることが分かる。
>>> Xc.T @ Xc / (m - 1)
array([[ 82.81818182, 127.54545455],
[127.54545455, 218.76363636]])numpy.ndarray.T — NumPy Manual
以上を関数にする。
def my_cov(*args: np.ndarray) -> np.ndarray:
X = np.column_stack(args)
n = X.shape[0]
j = np.ones((1, n))
# ブロードキャストされるので正方行列Jをかけた場合と同じ結果になる
Xc = X - j @ X / n
return Xc.T @ Xc / (n - 1)複数個の変数を受け取れるように、可変長引数 *args を利用している。
Pythonの可変長引数(*args, **kwargs)の使い方 | note.nkmk.me
実行例
>>> my_cov(weight, height)
array([[ 82.81818182, 127.54545455],
[127.54545455, 218.76363636]])numpy.cov() の実行例1(2つのベクトルを渡す)
>>> np.cov(weight, height)
array([[ 82.81818182, 127.54545455],
[127.54545455, 218.76363636]])numpy.cov() の実行例2(データ行列を渡す)
>>> np.cov(X.T) # 転置
array([[ 82.81818182, 127.54545455],
[127.54545455, 218.76363636]])注意: numpy.cov() に渡すデータは、行に変数を、列にサンプルの個体を並べる形式を取る。従って、実行例2のように pandas と同様のデータ行列の場合、転置しなければならない。
ちなみに、引数 bias=True にすると、 ではなく で割る。
>>> np.cov(weight, height, bias=True)
array([[ 75.2892562 , 115.95041322],
[115.95041322, 198.87603306]])更に ddof で bias の指定は上書きされる。
>>> np.cov(weight, height, ddof=0)
array([[ 75.2892562 , 115.95041322],
[115.95041322, 198.87603306]])pandas.DataFrame.cov() の実行例
>>> df = pd.DataFrame({"weight": weight, "height": height})
>>> df
weight height
0 42 138
1 46 150
2 53 152
3 56 163
4 58 164
5 61 167
6 62 165
7 63 182
8 65 180
9 67 180
10 73 183
>>> df.cov()
weight height
weight 82.818182 127.545455
height 127.545455 218.763636pandas.DataFrame.cov — pandas documentation
11 相関係数をわかりやすく解説
相関係数をわかりやすく解説【統計学入門11】 - 米国データサイエンティストのブログ
- 相関行列 (correlation matrix)
numpy.corrcoef(x, y=None)pandas.DataFrame.corr()
- 行列操作
- 行列の対角成分、対角行列:
numpy.diag(v, k=0) - ndarrayに次元を追加:
ndarray[:, np.newaxis]
- 行列の対角成分、対角行列:
相関係数 (correlation coefficient)
先ほど共分散で述べたように、共分散は偏差ベクトルの内積をで割ったものであった。同様に、標準偏差 は偏差ベクトル の ノルム を割ったものになる。
従って、コーシー・シュワルツの不等式 より、不等式
が成り立つ。そこで 相関係数 を
と定義すると、相関係数の範囲は
となる。相関係数の最小と最大に関して次のことが言える。
- 偏差ベクトル と の向きが同じ 変数と変数が 傾き正 で一直線上に並ぶ
- 偏差ベクトル と の向きが逆 変数と変数が 傾き負 で一直線上に並ぶ
def my_corrcoef(x: np.ndarray, y: np.ndarray) -> np.ndarray:
cov_mat = np.cov(x, y)
s_x_y = cov_mat[1, 0]
s_x, s_y = np.sqrt(np.diag(cov_mat))
return s_x_y / (s_x * s_y)4行目では共分散行列から対角成分のベクトルを取り出して、平方根を計算している。numpy.diag() 関数は、行列から対角成分の抽出にも、対角行列の生成にも使える。
numpy.diag — NumPy v2.4 Manual
実行例
>>> weight = np.array([42, 46, 53, 56, 58, 61, 62, 63, 65, 67, 73])
>>> height = np.array([138, 150, 152, 163, 164, 167, 165, 182, 180, 180, 183])
>>> my_corrcoef(weight, height)
np.float64(0.9475771359123567)相関行列 (correlation matrix)
分散共分散行列と同様に、 個の変数 () に対して、変数の相関係数を成分に持つ 次正方行列
を 相関行列 と呼ぶ。但し は、変数 と変数 の相関係数とする。対角成分は全てになる。
さて、分散共分散行列 の対角成分 (変数の分散)からなる 次対角行列を
とする。更に、 の対角成分の平方根の逆数(つまり標準偏差の逆数)を成分にもつ対角行列を
としたとき、相関行列は
で計算できる。対角行列を 左から かけると、行列 の対応する 行がスカラー倍 される。一方、対角行列を 右から かけると、行列 の対応する 列がスカラー倍 される。
def my_corrcoef(*args: np.ndarray) -> np.ndarray:
X = np.column_stack(args)
S = np.cov(X.T)
D_inv_std = np.diag(np.diag(S) ** (-1 / 2))
return D_inv_std @ S @ D_inv_std実行例
>>> my_corrcoef(weight, height)
array([[1. , 0.94757714],
[0.94757714, 1. ]])但し、この実装は np.diag() 関数を二重に使って、ゼロ埋め行列を生成するので効率が悪い。
アダマール積 * を利用した、別の実装を考える。 の対角成分からなるベクトル inv_std を計算する。
>>> inv_std = np.diag(S) ** (-1 / 2)
>>> inv_std
array([0.10988468, 0.06761023])inv_std を S にアダマール積でかけると、
>>> np.broadcast_to(inv_std, S.shape)
array([[0.10988468, 0.06761023],
[0.10988468, 0.06761023]])で確認できるように、自動的にブロードキャストされて、S の各 列 へのスカラー倍になる。
次に inv_std を転置して、列ベクトルに変換する。
>>> inv_std[:, np.newaxis]
array([[0.10988468],
[0.06761023]])NumPy配列ndarrayに次元を追加するnp.newaxis, np.expand_dims() | note.nkmk.me
これを S にアダマール積でかけると、
>>> np.broadcast_to(inv_std[:, np.newaxis], S.shape)
array([[0.10988468, 0.10988468],
[0.06761023, 0.06761023]])で確認できるように、自動的にブロードキャストされて、S の 行 へのスカラー倍になる。従ってこれらアダマール積でかけ合わせると、
>>> inv_std[:, np.newaxis] * S * inv_std
array([[1. , 0.94757714],
[0.94757714, 1. ]])相関行列が得られる。アダマール積を利用することで、効率が改善している。
以上を関数にまとめると、次のようになる。
def my_corrcoef(*args: np.ndarray) -> np.ndarray:
X = np.column_stack(args)
S = np.cov(X.T)
inv_std = np.diag(S) ** (-1 / 2)
return inv_std[:, np.newaxis] * S * inv_stdnumpy.corrcoef() の実行例
>>> np.corrcoef(weight, height)
array([[1. , 0.94757714],
[0.94757714, 1. ]])numpy.corrcoef — NumPy v2.4 Manual
pandas.DataFrame.corr() の実行例
>>> df = pd.DataFrame({"weight": weight, "height": height})
>>> df
weight height
0 42 138
1 46 150
2 53 152
3 56 163
4 58 164
5 61 167
6 62 165
7 63 182
8 65 180
9 67 180
10 73 183
>>> df.corr()
weight height
weight 1.000000 0.947577
height 0.947577 1.000000pandas.DataFrame.corr — pandas 3.0.2 documentation
12 これだけは知っておいた方がいい相関係数のポイント3つ
これだけは知っておいた方がいい相関係数のポイント3つ【統計学入門12】 - 米国データサイエンティストのブログ
実験: 相関係数の強弱を確かめる
相関係数の強弱を確かめるために、実際に乱数を生成してプロットする実験を行う。
その前に、講座で与えられた確率変数 が、所望の相関係数 になることを確かめる。まず確率変数 が互いに独立に標準正規分布に従うと仮定する。それぞれの共分散は0である。
のとき、確率変数を
と定めると、分散は
であり、共分散は
となるので、 の相関係数はとなる。
一方、 のときは、
と、正の平方根になるように定める。
相関係数はになる。
相関係数を変化させながら一覧でプロットしてみると、まさに百聞は一見にしかず。
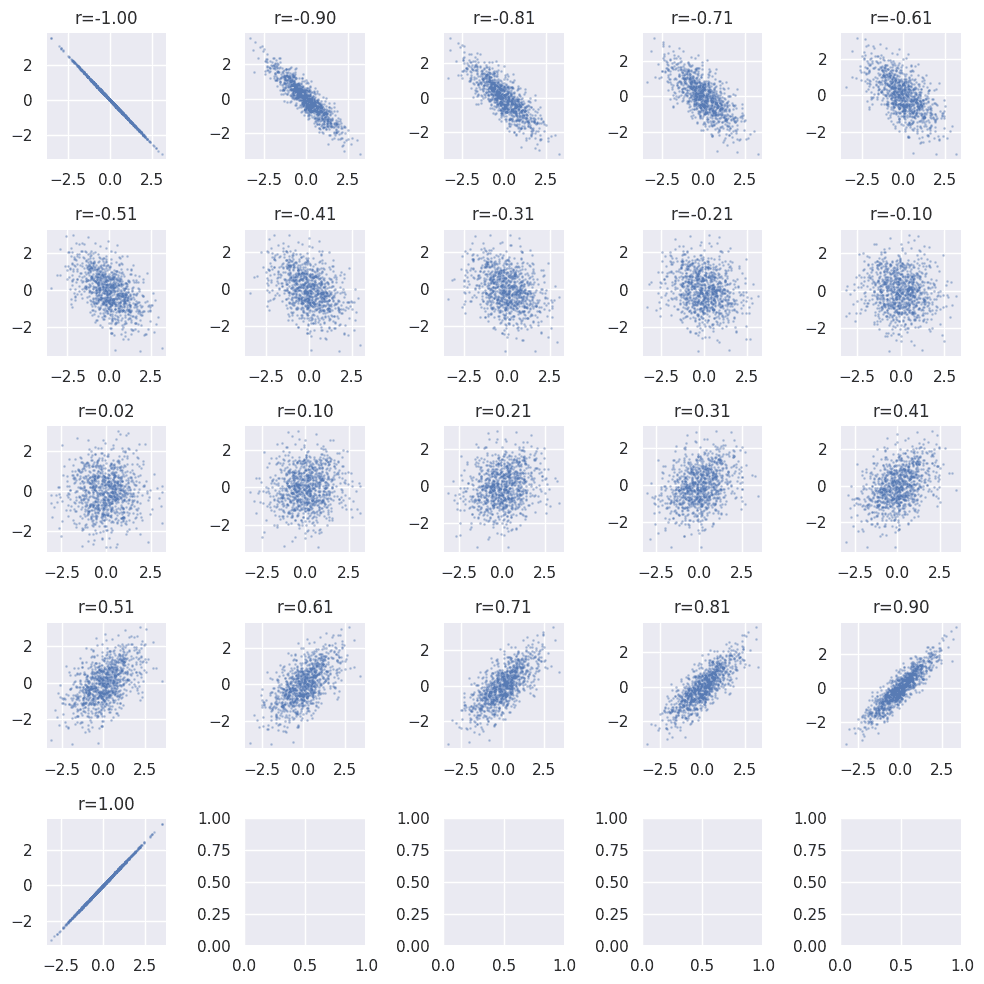
相関の大小の基準
- 0.7を超えたら相関は強い
- 0.2を下回るようなら相関はほぼない
13 回帰分析を図でわかりやすく解説!条件付き平均と最小二乗法って?
回帰分析を図でわかりやすく解説!条件付き平均と最小二乗法って?【統計学入門13】 - 米国データサイエンティストのブログ
- 散布図と回帰直線:
seaborn.regplot(data=None, *, x=None, y=None)seaborn.regplot(data=df, x="column name", y="column name"): DataFrameの場合seaborn.regplot(x=array_x, x=array_y): ndarrayの場合
補足(Seabornの関数の呼び出し方法): v0.11.0 で位置引数が非推奨になったことに伴い、v0.12 以降は記事のように sns.regplot(height, weight) と位置引数での呼び出しができなくなった。data が唯一の位置引数になり、他は キーワード引数で指定 する必要がある。
Release v0.12.0 · mwaskom/seaborn
呼び出し方法1: DataFrameを渡す(xとyは列名)
sns.regplot(data=df, x="height", y="weight")
呼び出し方法2: ndarray を渡す
sns.regplot(x=height, y=weight)
seaborn.regplot — seaborn 0.13.2 documentation
14 回帰直線の数式をイメージで理解する.回帰係数と相関係数の関係
回帰直線の数式をイメージで理解する.回帰係数と相関係数の関係【統計学入門14】 - 米国データサイエンティストのブログ
- 線形回帰:
sklearn.linear_model.LinearRegression()
最小2乗法
残差平方和を最小にする を求める。
に関して偏微分すると、正規方程式
が得られる。この連立方程式を解くと、
回帰係数が得られる。回帰係数 に関しては、講座にあるように が直感的で理解しやすいが、実際の計算は の方が単純。
回帰係数の計算法1 ()
>>> weight = np.array([42, 46, 53, 56, 58, 61, 62, 63, 65, 67, 73])
>>> height = np.array([138, 150, 152, 163, 164, 167, 165, 182, 180, 180, 183])
>>> S = np.cov(height, weight)
>>> b = S[0, 1] / S[0, 0]
>>> b
np.float64(0.583028590425532)回帰係数の計算法2 ()
>>> r = np.corrcoef(height, weight)[0, 1]
>>> s_x = np.std(height)
>>> s_y = np.std(weight)
>>> b = r * s_y / s_x
>>> b
np.float64(0.5830285904255318)計算法1 () で関数にまとめると以下のようになる。
def my_linear_regression(x: np.ndarray, y: np.ndarray):
S = np.cov(x, y)
b = S[0, 1] / S[0, 0]
a = np.mean(y) - b * np.mean(x)
return (a, b)実行例
>>> my_linear_regression(height, weight)
(np.float64(-37.949468085106396), np.float64(0.583028590425532))sklearn.linear_model.LinearRegression() の実行例
>>> from sklearn.linear_model import LinearRegression
>>> # 説明変数: 軸を追加して行列(列ベクトル)にする
>>> X = height[:, np.newaxis]
>>> # 目的変数
>>> y = weight
>>> # インスタンス作成
>>> reg = LinearRegression()
>>> # 学習
>>> reg.fit(X, y)
>>> # 学習結果
>>> print(f"b={reg.coef_}")
b=[0.58302859]
>>> print(f"a={reg.intercept_}")
a=-37.94946808510644
>>> # 予測
>>> X = np.array([[175]])
>>> y = reg.predict(X)
>>> print(X, y)
[[175]] [64.08053524]fit()メソッド: 学習predict()メソッド: 予測
LinearRegression — scikit-learn 1.8.0 documentation
16 決定係数R2を超わかりやすく解説
決定係数R2を超わかりやすく解説【統計学入門16】 - 米国データサイエンティストのブログ
決定係数のイメージに関しては、かめさんが講座で十分説明してくれているので、ここでは数学的な補足を少しだけ。
(補足)平方和の分解と決定係数
データ の偏差は
予測値 の偏差(右辺左側)と残差(右辺右側)に分けられる。最小2乗法では、予測値 は説明変数 が生成する空間への直交射影になるので、右辺は左辺の 直交分解 になっている(詳しいことは今回は省略)。従って、次式のように平方和の分解が成り立つ。
27-5. 決定係数と重相関係数 | 統計学の時間 | 統計WEB
左辺(「全変動」と呼ぶ)に対して、右辺左側(「回帰変動」と呼ぶ)は説明変数で 説明される変動、右辺右側(「残差変動」と呼ぶ)は説明変数で 説明されない変動 と考えられる。
そこで、全変動のうち 説明変数で説明される割合 を 決定係数 と定義する。
(補足)決定係数と相関係数の関係
最小2乗法では なので、
と分子を変形する。更に を代入すると、
つまり、最小2乗法では決定係数は相関係数の平方になる。
17 決定係数R2で回帰式の精度を評価する
決定係数R2で回帰式の精度を評価する【統計学入門17】 - 米国データサイエンティストのブログ
- 決定係数:
sklearn.metrics.r2_score(y_true, y_pred)
先ほど定義した決定係数 を実装する。引数 y_true はデータ y を、y_pred は予測値 を表す。
def my_r2_score(y_true: np.ndarray, y_pred: np.ndarray):
S_t = np.sum((y_true - np.mean(y_true)) ** 2)
S_e = np.sum((y_true - y_pred) ** 2)
return 1 - S_e / S_t講座では学習データと評価データに分けて、評価データで決定係数を計算している。
実行例
>>> # 評価データ
>>> weight_test = np.array([43, 45, 50, 58, 58, 60, 66, 63, 65, 70, 72])
>>> height_test = np.array([140, 148, 152, 163, 160, 170, 163, 177, 177, 185, 180])
>>> # 予測値
>>> X_test = height[:, np.newaxis]
>>> y_test_pred = reg.predict(X_test)
>>> # 決定係数
>>> my_r2_score(weight_test, y_test_pred)
np.float64(0.8569626575763964)sklearn.metrics.r2_score() の実行例
>>> from sklearn.metrics import r2_score
>>> r2_score(weight_test, y_test_pred)
0.8569626575763964