「データサイエンス講座(統計編)」(かめ@米国データサイエンティストさん)のノートです。内容は、第2回「代表値」から第9回「標準化」まで、内容は 1変数の記述統計学 となります。
データサイエンス講座(統計編) - 米国データサイエンティストのブログ
このノートは、統計検定2級以上の人が「Pythonで実践しながら理論を確かめつつ理解を深化させる」という方針で書かれています。すべての統計量は最初に スクラッチ実装 した上で、NumPy、SciPy、Pandasなどの関数の使い方を確認するという構成になっています。
統計検定の勉強をしていたときは、紙とペンを使って理論を理解することに重点を置いていました。しかし、実践も大切です。今回、統計量を Python で実装する過程で、新しい発見が幾つかありました。
- 幾何平均:桁溢れしにくい計算方法
- 分位数:隣接する要素の平均だけでなく、内分するように補間
- 「不偏」標準偏差:不偏ではない
強力な計算力を持つコンピューターを利用することで、理解をより強固にすることができます。例えば、理論的には不偏分散は不偏推定量であるはずですが、標本抽出を繰り返して本当に母分散に近くなることが確かめられます。
各回の冒頭に関数を列挙しているので、逆引きリファレンス としても利用できます。
気になる方は、かめ@米国データサイエンティストさんの講座のお供に、ぜひこの記事も読んでみてください!JupyterLabのノートブックは こちら にあります。
また、この講座の前の データサイエンスのためのPython入門講座(かめ@米国データサイエンティスト)のノート | ゼータへの旅路 / Journey to Zeta でも、各種ライブラリについて補足説明をしています。是非よろしくお願いします。
2 代表値とは(実は色々ある平均の種類)
代表値とは(実は色々ある平均の種類)【統計学入門②】 - 米国データサイエンティストのブログ
- 算術平均 (arithmetic mean):
numpy.mean() - 幾何平均 (geometric mean):
scipy.stats.gmean() - 調和平均 (harmonic mean):
scipy.stats.hmean()
算術平均 (arithmetic mean)
def my_mean(x):
return np.sum(x) / len(x)実行例
>>> apple_weights = [295, 300, 300, 310, 311]
>>> my_mean(apple_weights)
np.float64(303.2)numpy.mean() の実行例
>>> np.mean(apple_weights)
np.float64(303.2)幾何平均 (geometric mean)
定義通りに計算すると、総積の計算で桁があふれてしまう。右側の式を利用して、一度対数に変換すると桁あふれが防げる。
def my_gmean2(x):
return np.exp(np.mean(np.log(x)))実行例
>>> a = np.arange(1, 101)
>>> a
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
...
92, 93, 94, 95, 96, 97, 98, 99, 100])
>>> my_gmean2(a)
np.float64(37.992689344834304)scipy.stats.gmean() の実行例
>>> stats.gmean(a)
np.float64(37.992689344834304)調和平均 (harmonic mean)
逆数の平均の逆数
def my_hmean(x):
return 1 / np.mean(1 / x)実行例
>>> velocities = np.array([20, 60])
>>> my_hmean(velocities)
np.float64(30.0)scipy.stats.hmean() の実行例
>>> stats.hmean(velocities)
np.float64(30.0)3 他にもある代表値(中央値と最頻値のポイント)
他にもある代表値(中央値と最頻値のポイント)【統計学入門③】 - 米国データサイエンティストのブログ
- 中央値 (median):
numpy.median() - 最頻値 (mode):
scipy.stats.mode()←最頻値を 一つだけ 返す(複峰でも)- 補足: pandas の
mode()は 複数 返す
- 補足: pandas の
中央値 (median)
ソートされた ndarray を y、y のサイズを n とする。
nが奇数の場合:yの 番目の値nが偶数の場合:yの 番目の値と 番目の値の平均- 補足:
ndarryのインデックスは0から始まる - 補足: は床関数(小数点以下の切り捨て)
def my_median(x):
y = np.sort(x)
n = len(x)
i = n // 2
# 奇数サイズの場合
if n % 2 == 1:
return y[i]
# 偶数サイズの場合
return np.mean(y[i - 1 : i + 1])実行例(偶数サイズの場合)
>>> a = np.array([1, 3, 2, 4, 5, 0])
>>> my_median(a)
np.float64(2.5)実行例(奇数サイズの場合)
>>> a = np.array([1, 3, 2, 4, 0])
>>> my_median(a)
np.int64(2)numpy.median() の実行例
>>> np.median(a)
np.float64(2.0)最頻値 (mode)
def my_mode(x):
u, counts = np.unique_counts(x)
return (u[np.argmax(counts)], np.max(counts))実行例
>>> a = np.array([6, 2, 4, 5, 1, 3, 5, 3, 4])
>>> my_mode(a)
(np.int64(3), np.int64(2))scipy.stats.mode() の実行例
>>> stats.mode(a)
ModeResult(mode=np.int64(3), count=np.int64(2))3 以外にも、4, 5 も2回出現するが、scipy.stats.mode() は 3 だけ返す。
補足: 複峰の場合
def my_mode_mm(x):
u, counts = np.unique_counts(x)
max_count = np.max(counts)
return (u[counts == max_count], max_count)実行例
>>> a = np.array([6, 2, 4, 5, 1, 3, 5, 3, 4])
my_mode_mm(a)
(array([3, 4, 5]), np.int64(2))pandas の pandas.Series.mode() は 複数 返す。
pandas.Series.mode() の実行例
>>> pd.Series(a).mode()
0 3
1 4
2 5
dtype: int64pandas.Series.mode — pandas documentation
4 ばらつきを表す散布度(範囲と四分位数を使う)
ばらつきを表す散布度(範囲と四分位数を使う)【統計学入門④】 - 米国データサイエンティストのブログ
- 範囲 (range):
numpy.ptp()(Peak to Peak の略) - 分位数 (Quantile):
numpy.quantile(a, q)- パーセンタイル (Percentile、1%刻み):
numpy.percentile(a, q)
- パーセンタイル (Percentile、1%刻み):
- 四分位範囲(interquartile range: IQR):
scipy.stats.iqr() - 四分位偏差(quartile deviation: QD)
範囲 (range)
範囲 (range) =
def my_ptp(x):
return np.max(x) - np.min(x)実行例
>>> dogs = np.array([10, 13, 17, 20, 29])
>>> my_ptp(dogs)
np.int64(19)numpy.ptp() の実行例
>>> dogs = np.array([10, 13, 17, 20, 29])
>>> numpy.ptp(dogs)
np.int64(19)(補足)分位数 (Quantile)
x は ndarray、q は確率(実数 )とする。中央値と同様に、x をソートした配列を y、y のサイズを n とする。
y の 番目の値 y[t] を、q分位数 (q-Quantile) とする。これは、y[0] から y[n-1] までを、長さ の線分に見立てて、 で内分する点と考えると分かりやすい。
当然 は整数とは限らない。そこで、 を
- :
tの整数部分 - :
tの小数部分
と分けて、次のように隣接する要素から補間して計算する。
def my_quantile(x, q):
y = np.sort(x)
n = len(y)
# 内分点
t = q * (n - 1)
j = int(t) # 整数部分
g = t - j # 小数部分
return (1 - g) * y[j] + g * y[j + 1]実行例
>>> a = np.arange(1, 7)
>>> a
array([1, 2, 3, 4, 5, 6])
>>> (my_quantile(a, 0.25), my_quantile(a, 0.5), my_quantile(a, 0.75))
(np.float64(2.25), np.float64(3.5), np.float64(4.75))numpy.quantile() の実行例
>>> np.quantile(a, (0.25, 0.5, 0.75))
array([2.25, 3.5 , 4.75])補足: q = 0.5 のとき、先ほどの中央値と等しくなる。
補足: これ以外にも、4-2. 四分位数を見てみよう | 統計学の時間 | 統計WEB のように、データを2等分して、小さい値のグループと大きい値のグループのそれぞれの中央値を四分位数とする方法もある。
四分位範囲 (IQR) と四分位偏差 (QD)
四分位範囲 (IQR) =
def my_iqr(x):
return np.quantile(x, 0.75) - np.quantile(x, 0.25)実行例
>>> data = [33, 35, 36, 39, 43, 49, 51, 54, 54, 56, 62, 64, 64, 69, 70]
>>> my_iqr(data)
np.float64(22.0)scipy.stats.iqr() の実行例
>>> stats.iqr(data)
np.float64(22.0)四分位偏差 (QD) =
def my_qd(x):
return stats.iqr(x) / 2実行例
>>> my_qd(data)
np.float64(11.0)5 絶対にわかる分散と標準偏差(超重要)
絶対にわかる分散と標準偏差(超重要)【統計学入門⑤】 - 米国データサイエンティストのブログ
- 平均偏差 MD
- 分散 :
numpy.var(a, ddof=0) - 標準偏差 :
numpy.std(a, ddof=0)
平均偏差 (mean deviation)
MD =
def my_md(x):
return np.sum(np.abs(x - np.mean(x))) / len(x)実行例
>>> samples = [10, 10, 11, 14, 15, 15, 16, 18, 18, 19, 20]
>>> my_md(samples)
np.float64(2.826446280991735)分散 (variance)
分散
def my_var(x):
return np.sum((x - np.mean(x)) ** 2) / len(x)実行例
>>> my_var(samples)
np.float64(11.537190082644628)numpy.var() の実行例
>>> np.var(samples)
np.float64(11.537190082644628)補足: ddof (Delta Degrees of Freedom) 引数で自由度が指定できる。デフォルトでは ddof = 0 で、ddof = 1 とすれば不偏分散になる。
標準偏差 (standard deviation)
標準偏差
def my_std(x):
return np.sqrt(np.var(x))実行例
>>> my_std(samples)
np.float64(3.3966439440489826)numpy.std() の実行例
>>> np.std(samples)
np.float64(3.3966439440489826)補足: numpy.var() と同様に、ddof (Delta Degrees of Freedom) 引数で自由度が指定できる。
6 不偏分散ってなに??なぜ標本分散は母集団分散より小さくなるのか
不偏分散ってなに??なぜ標本分散は母集団分散より小さくなるのか【統計学入門⑥】 - 米国データサイエンティストのブログ
- 分散の期待値 母分散
- 実験: 標本分布を見てみる
numpy.random.Generator.choice(a, size=None): 標本抽出
- 数学的裏付け: 算術平均の性質
(標本)分散 は母分散 より小さくなる傾向がある。実際に
が成り立つ。
実験: 分散の標本分布と平均
まず population を母集団として、母分散を計算する。
>>> population = np.array([1, 5, 10, 11, 14, 15, 15, 16, 18, 18, 19, 20, 25, 30])
>>> np.var(population)
np.float64(51.392857142857146)次に標本(サイズ3)を抽出して、標本分散を計算する(反復回数10,000回)。
>>> num_of_samples = 10_000
>>> rng = np.random.default_rng(1728)
>>> sample_vals = [
np.var(rng.choice(population, size=3, replace=True)) for _ in range(num_of_samples)
]numpy.random.Generator.choice — NumPy Manual
標本分散の分布、標本分布を見てみる。
>>> sns.set_theme()
>>> fig, axes = plt.subplots()
>>> sns.histplot(sample_vals, bins="auto", kde=True, ax=axes)
>>> plt.show()
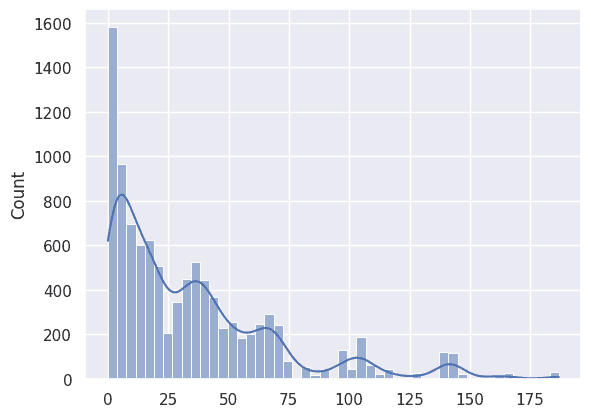
全体的に母分散 より小さそうだ。
>>> np.mean(sample_vals)
np.float64(34.40917777777778)実際に標本分散 の平均は 34.41 で、母分散より小さい。
数学的裏付け: 算術平均の性質
標本平均 は、 を最小にする として特徴づけられる。従って とした場合、
が成り立つ。両辺を で割ると、
であり、両辺の期待値を取ると、
が成り立つ。実際には等号を含まないだが、それは次の回で示す。
7 超わかりやすい!不偏分散がn-1で割る理由!不偏性とは
超わかりやすい!不偏分散がn-1で割る理由!不偏性とは【統計学入門⑦】 - 米国データサイエンティストのブログ
- 不偏分散
scipy.stats.tvar()pandas.Series.var()
- 「不偏」標準偏差 (corrected sample standard deviation)
scipy.stats.tstd()pandas.Series.std()
標本平均の不偏性と分散
標本平均の期待値
標本平均の分散
分散の2番目の等式は、確率変数 の独立性より成り立つ。
標本平均は母平均の不偏推定量で、サンプルサイズが大きくなるほど標本分布の分散が小さくなることが分かる。
実験: 標本平均の標本分布と平均
前回と同じ母集団 population を考える。母平均は 15.5、母分散は 51.392857142857146 である。
>>> population = np.array([1, 5, 10, 11, 14, 15, 15, 16, 18, 18, 19, 20, 25, 30])
>>> np.mean(population)
np.float64(15.5)
>>> np.var(population)
np.float64(51.392857142857146)サンプルサイズ 5
標本抽出。標本のサイズは 5 で、標本の数(反復回数)は 10,000 とする。
>>> sample_size = 5
>>> num_of_samples = 10_000
>>> rng = np.random.default_rng(1728)
>>> samples = [rng.choice(population, size=sample_size) for _ in range(num_of_samples)]全ての標本に対して、標本平均を計算する。
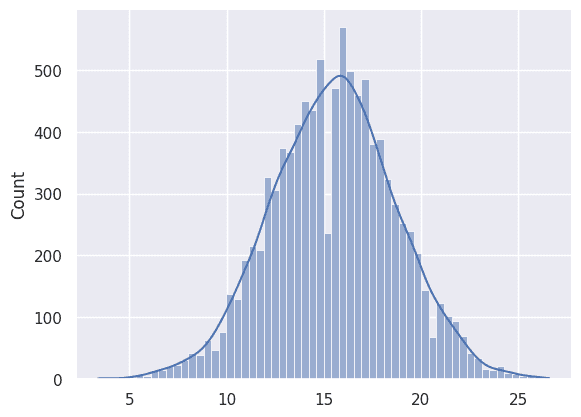
>>> samples_mean = [np.mean(sample) for sample in samples]ヒストグラムで標本分布を見てみる。
>>> sns.set_theme()
>>> fig, axes = plt.subplots()
>>> sns.histplot(samples_mean, bins='auto', kde=True, ax=axes)
>>> plt.show()
# 標本平均の平均
>>> np.mean(samples_mean)
np.float64(15.513679999999999)
# 標本平均の分散
>>> np.var(samples_mean)
np.float64(10.2560928576)
# 分散の理論値
>>> np.var(population) / sample_size
np.float64(10.278571428571428)標本平均の平均も分散も理論値に近そうだ。
サンプルサイズ 10
サンプルサイズを大きくして、標本抽出する。
>>> sample_size = 10
>>> num_of_samples = 10_000
>>> rng = np.random.default_rng(1728)
>>> samples = [rng.choice(population, size=sample_size) for _ in range(num_of_samples)]
>>> samples_mean = [np.mean(sample) for sample in samples]
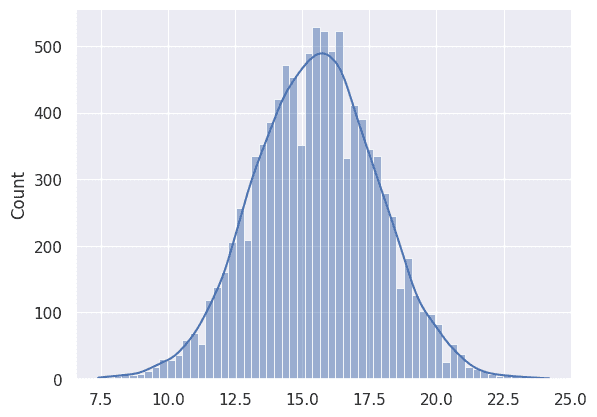
標本平均の平均と分散を計算する。
>>> print(f"sample mean: {np.mean(samples_mean)}")
>>> print(f"theoretical mean: {np.mean(population)}")
>>> print(f"sample variance: {np.var(samples_mean)}")
>>> print(f"theoretical variance: {np.var(population) / sample_size}")
sample mean: 15.512579999999998
theoretical mean: 15.5
sample variance: 5.2619737436
theoretical variance: 5.139285714285714サンプルサイズ 5 のよりも、標本分布の分散が小さくなっている。
不偏分散と不偏性
右辺の第2項を移項して、両辺に期待値を取る。
従って
が示せた。母分散の不偏推定量である第3項 を、不偏分散と呼ぶ。
def my_unbiased_var(x):
return np.sum((x - np.mean(x)) ** 2) / (len(x) - 1)実行例
# 標本抽出
>>> rng = np.random.default_rng(1728)
>>> sample = rng.choice(population, size=3)
>>> sample
array([ 5, 19, 14])
# 不偏分散
>>> my_unbiased_var(sample)
np.float64(50.333333333333336)numpy.var() の実行例
>>> np.var(sample, ddof=1)
np.float64(50.333333333333336)scipy.stats.tvar() の実行例
>>> stats.tvar(sample)
np.float64(50.333333333333336)pandas.Series.var() の実行例
>>> pd.Series(sample).var()
np.float64(50.333333333333336)pandas.Series.var — pandas documentation
(補足)実験: 不偏分散の標本分布と平均
母集団は先ほどと同じ、サンプルサイズ 3 で標本抽出する。
>>> sample_size = 3
>>> num_of_samples = 10_000
>>> rng = np.random.default_rng(1728)
>>> samples = [rng.choice(population, size=sample_size) for _ in range(num_of_samples)]
>>> samples_unbiased_var = [np.var(sample, ddof=1) for sample in samples]
>>> np.mean(samples_unbiased_var)
np.float64(51.61376666666666)不偏分散の平均は、母分散 (51.392857142857146) に近いことが確かめられる。
「不偏」標準偏差 (corrected sample standard deviation)
不偏分散 は母分散の不偏推定量であるが、この は母標準偏差の 不偏推定量ではない。しかし、分散 から計算される標準偏差 と区別する為に、ここでは敢えて「不偏」標準偏差と呼ぶことにする。
def my_corrected_std(x):
return np.sqrt(np.var(x, ddof=1))実行例
# 標本抽出
>>> rng = np.random.default_rng(1728)
>>> sample = rng.choice(population, size=3)
>>> sample
array([ 5, 19, 14])
# 「不偏」標準偏差
>>> my_corrected_std(sample)
np.float64(7.094598884597588)numpy.std() の実行例
>>> np.std(sample, ddof=1)
np.float64(7.094598884597588)scipy.stats.tstd() の実行例
>>> stats.tstd(sample)
np.float64(7.094598884597588)pandas.Series.std() の実行例
>>> pd.Series(sample).std()
np.float64(7.094598884597588)pandas.Series.std — pandas documentation
(補足)実験: 「不偏」標準偏差の標本分布と平均
先ほどの不偏分散と同じサンプルで、「不偏」標準偏差 s を計算してみる。
# 母集団の標準偏差
>>> np.std(population)
np.float64(7.168881163951398)
# 「不偏」標準偏差 `s` の平均
>>> samples_corrected_std = [np.std(sample, ddof=1) for sample in samples]
>>> np.mean(samples_corrected_std)
np.float64(6.254145131582969)
# 標準偏差 `S` の平均
>>> np.mean([np.std(sample, ddof=0) for sample in samples])
np.float64(5.106488116563278)母集団の標準偏差に対して、実際にその平均は偏っている事が確認できる。ただ、標準偏差 S よりかは、「不偏」標準偏差 s の方が母数に近そうだ。
8 標準偏差から散らばり具合をどう読み取る?
標準偏差から散らばり具合をどう読み取る?【統計学入門⑧】 - 米国データサイエンティストのブログ
標準偏差の範囲内に収まるデータの割合を、実験で確かめる。
- 乱数生成
- 正規分布:
numpy.random.Generator.normal() - 連続一様分布:
numpy.random.Generator.uniform()
- 正規分布:
- 連続確率分布の基底クラス:
scipy.stats.rv_continuous- 累積分布関数:
scipy.stats.<PD>.cdf() - 期待値:
scipy.stats.<PD>.mean() - 標準偏差:
scipy.stats.<PD>.std() <PD>には確率分布の名前が入る- 正規分布の各種関数:
scipy.stats.norm - 連続一様分布の各種関数:
scipy.stats.uniform
- 正規分布の各種関数:
- 累積分布関数:
Random Generator — NumPy Manual
実験: 標準正規分布
- 正規分布の確率(理論値)
- : 68%
- : 95%
- : 99.7%
標準正規分布から乱数生成
>>> sample_size = 10_000
>>> rng = np.random.default_rng(1728)
>>> randoms = rng.normal(size=sample_size)numpy.random.Generator.normal — Manual
平均と標準偏差を計算。ほぼ理論値どおり。
>>> t_mean = stats.norm.mean()
>>> t_std = stats.norm.std()
>>> print(f"theoretical mean: {t_mean}")
>>> print(f"sample mean: {np.mean(randoms)}")
>>> print(f"theoretical SD: {t_std}")
>>> print(f"sample SD: {np.std(randoms)}")
theoretical mean: 0.0
sample mean: 0.007775986045111138
theoretical SD: 1.0
sample SD: 1.005538212685025scipy.stats.norm — SciPy Manual
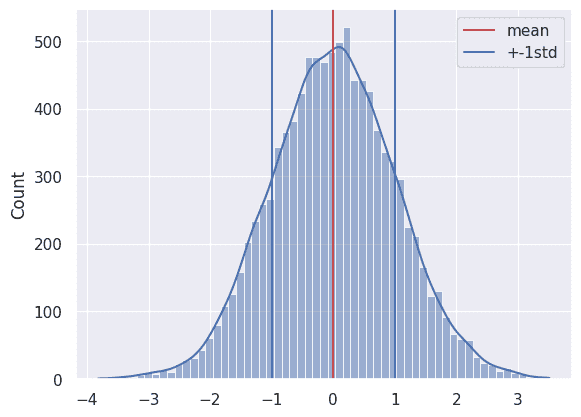
の場合
の範囲内のデータを数える。理論値68.3%に対して、サンプルは67.93%。
>>> coef = 1
>>> thresh = coef * t_std
>>> range_low, range_high = t_mean - thresh, t_mean + thresh
# サンプル
>>> np.count_nonzero((range_low < randoms) & (randoms < range_high)) / sample_size
np.float64(0.6793)
# 理論値
>>> stats.norm.cdf(range_high) - stats.norm.cdf(range_low)
np.float64(0.6826894921370859)補足: np.count_nonzero() 関数で ndarray の条件に該当する要素を数えることができる。
numpy.count_nonzero — NumPy Manual
ヒストグラム
sns.set_theme()
fig, axes = plt.subplots()
sns.histplot(randoms, bins="auto", kde=True, ax=axes)
axes.axvline(t_mean, color="r", label="mean")
axes.axvline(range_low, color="b", label=f"+-{coef}std")
axes.axvline(range_high, color="b")
axes.legend()
plt.show()matplotlib.axes.Axes.axvline — Matplotlib documentation
の場合
>>> coef = 2
>>> thresh = coef * t_std
>>> range_low, range_high = t_mean - thresh, t_mean + thresh
# サンプル
>>> np.count_nonzero((range_low < randoms) & (randoms < range_high)) / sample_size
np.float64(0.954)
# 理論値
>>> stats.norm.cdf(range_high) - stats.norm.cdf(range_low)
np.float64(0.9544997361036416)の場合
>>> coef = 3
>>> thresh = coef * t_std
>>> range_low, range_high = t_mean - thresh, t_mean + thresh
# サンプル
>>> np.count_nonzero((range_low < randoms) & (randoms < range_high)) / sample_size
np.float64(0.9966)
# 理論値
>>> stats.norm.cdf(range_high) - stats.norm.cdf(range_low)
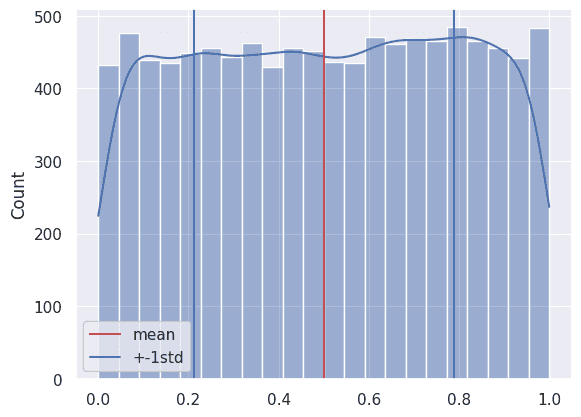
np.float64(0.9973002039367398)実験: 連続一様分布
乱数生成
>>> sample_size = 10_000
>>> rng = np.random.default_rng(1728)
>>> randoms = rng.uniform(size=sample_size)期待値0.5、標準偏差0.289
>>> t_mean = stats.uniform.mean()
>>> t_std = stats.uniform.std()
>>> print(f"theoretical mean: {t_mean}")
>>> print(f"sample mean: {np.mean(randoms)}")
>>> print(f"theoretical SD: {t_std}")
>>> print(f"sample SD: {np.std(randoms)}")
theoretical mean: 0.5
sample mean: 0.5047497968727819
theoretical SD: 0.28867513459481287
sample SD: 0.28941943204801124scipy.stats.uniform — SciPy Manual
正規分布と同様に の範囲内のデータを数える。
>>> coef = 1
>>> thresh = coef * t_std
>>> range_low, range_high = t_mean - thresh, t_mean + thresh
# サンプル
>>> np.count_nonzero((range_low < randoms) & (randoms < range_high)) / sample_size
np.float64(0.5775)
# 理論値
>>> stats.uniform.cdf(range_high) - stats.uniform.cdf(range_low)
np.float64(0.5773502691896257)ほぼ理論値通り57.75%だが、正規分布の68%とは大分異なる。
補足: チェビシェフの不等式
確率論では、確率変数 に対して
が成り立つ。これによれば、確率分布とは 無関係に 少なくとも
- : 75% 以上
- : 88.9% 以上
となる。
2-3. チェビシェフの不等式 | 統計学の時間 | 統計WEB
9 超重要!標準化と偏差値ってなに??z得点とT得点
超重要!標準化と偏差値ってなに??z得点とT得点【統計学入門⑨】 - 米国データサイエンティストのブログ
- 標準化: z得点
scipy.stats.zscore()sklearn.preprocessing.StandardScaler.fit_transform(X)
z得点
def my_zscore(x):
return (x - np.mean(x)) / np.std(x)実行例
>>> data = [0, 10, 20, 25, 27, 30, 43, 56, 68, 70]
>>> z = my_zscore(data)
>>> z
array([-1.54799532, -1.10444365, -0.66089199, -0.43911615, -0.35040582,
-0.21734032, 0.35927685, 0.93589402, 1.46815602, 1.55686636])
>>> print(f"mean: {np.mean(z):.2f}")
>>> print(f"std: {np.std(z):.2f}")
mean: 0.00
std: 1.00平均が0、標準偏差が1になっている。
scipy.stats.zscore() の実行例
>>> stats.zscore(data)
array([-1.54799532, -1.10444365, -0.66089199, -0.43911615, -0.35040582,
-0.21734032, 0.35927685, 0.93589402, 1.46815602, 1.55686636])sklearn.preprocessing.StandardScaler.fit_transform(X) の実行例
# StandardScalerインスタンス作成
>>> scaler = StandardScaler()
# 標準化
>>> scaler.fit_transform(np.expand_dims(data, axis=-1))
array([[-1.54799532],
[-1.10444365],
[-0.66089199],
[-0.43911615],
[-0.35040582],
[-0.21734032],
[ 0.35927685],
[ 0.93589402],
[ 1.46815602],
[ 1.55686636]])注意: StandardScalerは2次元配列である必要があるので、numpy.expand_dims(axis=-1) で予め次元を増やしている。
StandardScaler — scikit-learn documentation
偏差値(T-score)
def my_tscore(x):
return 10 * stats.zscore(x) + 50実行例
>>> t = my_tscore(data)
>>> t
array([34.52004677, 38.95556346, 43.39108014, 45.60883848, 46.49594182,
47.82659682, 53.59276851, 59.3589402 , 64.68156023, 65.56866356])
>>> print(f"mean: {np.mean(t):.2f}")
>>> print(f"std: {np.std(t):.2f}")
mean: 50.00
std: 10.00平均が50、標準偏差が10になっている。