「データサイエンスのためのPython入門講座(かめ@米国データサイエンティスト)」のノートです。
データサイエンスのためのPython入門講座全33回〜目次とまとめ〜 - 米国データサイエンティストのブログ
この講座はPythonとデータサイエンス関連ライブラリの基本がコンパクトにまとまっていて、Python入門者や復習したい人にも非常にオススメの内容となっています。
しかし2020年03月に公開された記事なので、残念ながら少し古くなっている部分もありました。そこで更新した方が良さそうな部分、そして個人的に躓いた部分などを、こちらにノートとして整理しておこうと思います。
プロジェクトの構成
PythonのコードはJupyterLabで動かします。プロジェクトは↓こちらより。
https://github.com/tally1728/usds-notes
- Docker Compose + uv
- Python 3.14 (w/ GIL)
- JupyterLab 4.5
- ライブラリ
- NumPy 2.4
- pandas 3.0
- matplotlib 3.10
- Seaborn 0.13
- OpenCV 4.13
Dockerを使っていますが、ローカルにuvがインストールされている場合は、uv単体でも動きます。macOSなどLinux以外では、uv単体の方がメモリ消費が節約できると思います。
LinuxでDocker(実際にはcontainerd+nerdctl)を、またmacOSでuvを利用して、動作確認済です。
使い方
Docker の場合
$ docker compose up
uv 単体の場合
ライブラリのインストール
$ uv sync --frozen
JupyterLabを開始
$ uv run jupyter lab --notebook-dir=notebooks
NumPy
https://github.com/tally1728/usds-notes/blob/main/notebooks/python-06—09-numpy.ipynb
Python入門6 はじめてのNumpy
データサイエンスのためのPython入門⑥〜はじめてのNumpy〜 - 米国データサイエンティストのブログ
ブロードキャスト
ndarray同士の演算で、shapeが異なる場合でも上手く演算できるように、自動的に形状の変形(ブロードキャスト)が行われる。
片方が行ベクトルのとき
>>> array1 = np.array([1, 2])
>>> array1.shape
(2,)>>> array2 = np.array([[1, 2], [3, 4], [5, 6]])
>>> array2.shape
(3, 2)このときarray1が自動的に(3, 2)型にブロードキャストされる。
>>> array1 + array2
array([[2, 4],
[4, 6],
[6, 8]])ちなみに、broadcast_to()関数でブロードキャストで変形結果が確認できる。
>>> np.broadcast_to(array1, (3, 2))
array([[1, 2],
[1, 2],
[1, 2]])また、列ベクトルのときも同様に
>>> array1 = np.array([[1], [2], [3]])
>>> array1.shape
(3, 1)>>> np.broadcast_to(array1, (3, 2))
array([[1, 1],
[2, 2],
[3, 3]])と変形されて
>>> array1 + array2
array([[2, 4],
[4, 6],
[6, 8]])となる。
以上のように、ブロードキャストはスカラー、行ベクトル、及び列ベクトルなど、変形前のサイズが1(1行または1列)の場合に対して有効。
一方で、次のように行数2の行列、つまりサイズが1でない場合、ブロードキャストできない。
>>> array1 = np.array([[1, 2], [3, 4]])
>>> array1.shape
(2, 2)>>> array2 = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
>>> array2.shape
(4, 2)>>> array1 + array2
ValueError: operands could not be broadcast together with shapes (2,2) (4,2)NumPyのブロードキャスト(形状の自動変換) | note.nkmk.me
Broadcasting — NumPy v2.4 Manual
Python入門8 NumPyでよく使う行列生成
乱数生成
NumPy1.17 (2019/7) 以降、Generatorを利用する方法が推奨されている。
>>> rng = np.random.default_rng(1728)
>>> rng.random()
0.7665956828605809numpy.random.default_rng(seed=None)関数はGeneratorオブジェクトを生成する。Generatorは各種確率分布から乱数を生成するメソッドを持っていて、例えばrandom()メソッドはの連続一様分布より乱数を生成する。
random.Generator.uniform(low=0.0, high=1.0, size=None)メソッド: 連続一様分布random.Generator.random(size=None, dtype=np.float64, out=None)メソッド:
random.Generator.normal(loc=0.0, scale=1.0, size=None)メソッド: 正規分布random.Generator.integers(low, high=None, size=None, dtype=np.int64, endpoint=False)メソッド: 離散一様分布
例: 標準正規分布から3行4列の乱数行列を生成
>>> rng.normal(size=(3, 4))
array([[-1.41426816, -0.42325657, 1.40363505, 0.35663045],
[-0.40824753, 0.93338735, 0.45316263, -0.32732742],
[ 1.02581572, -1.20693684, 0.88650372, -0.2765314 ]])NumPy, randomで乱数生成(np.random.rand, normalなど) | note.nkmk.me
Random sampling — NumPy v2.4 Manual
Python入門9 NumPyでよく使う便利関数
データサイエンスのためのPython入門⑨〜NumPyでよく使う便利関数〜 - 米国データサイエンティストのブログ
numpy.squeeze(ndarray, axis=None)関数は、shapeで1になっている次元を まとめて 削減する。
例えば、最初と最後の次元のサイズが1になってる配列
>>> ndarray = np.arange(1, 10).reshape(3, 3)
>>> ndarray = np.expand_dims(ndarray, axis=-0)
>>> ndarray = np.expand_dims(ndarray, axis=-1)
>>> ndarray.shape
(1, 3, 3, 1)に対して、squeezeすると
>>> ndarray = np.squeeze(ndarray)
>>> ndarray.shape
(3, 3)サイズが1の次元が消えて、形状が(3, 3)になる。
NumPy配列ndarrayのサイズ1の次元を削除するnp.squeeze() | note.nkmk.me
numpy.squeeze — NumPy v2.4 Manual
pandas
https://github.com/tally1728/usds-notes/blob/main/notebooks/python-10—19-pandas.ipynb
ちょうど2026年1月にpandas 3がリリースされた。pandas 3には幾つかの破壊的変更が含まれる。その中でも、Copy-on-Write の有効化に伴う 連鎖代入 の挙動の変更には、注意が必要。Copy-on-Writeでは、連鎖代入における中間オブジェクトが コピー として扱われる。
講座にある欠損値の平均値代入を例に見てみよう。
例1: 再代入
df["Age"] = df["Age"].fillna(df["Age"].mean())
これをメソッド毎に分解すると
_copy1 = df["Age"]
_copy2 = _copy1.fillna(df["Age"].mean())
df["Age"] = _copy2のようになり、最初の行では元のdfへの副作用なしに_copy1が生成され、2行目では_copy1への副作用なしに_copy2が生成される。dfのAgeカラムに_copy2が代入されて、最終的にdfが更新される。
一方で、連鎖代入を伴う次のコードを考える。
例2: 連鎖代入 (inplace)
df['Age'].fillna(df['Age'].mean(), inplace=True)
これもメソッド毎に分解してみると
_copy1 = df["Age"]
_copy1.fillna(df["Age"].mean(), inplace=True)のようになり、2行目はinplaceの変更なので_copy1は変更されるが、元のdfは変化しない。その挙動が紛らわしいので、pandas 3では連鎖代入が禁止され、例2のようなコードではChainedAssignmentErrorが発生するようになった。
幸いにも、講座のコードは全て例1のような再代入の形式になっており、pandas 3でも問題なく動作した。
pandas 3リリース🎉破壊的変更とv2/v3互換コードの書き方 #Python - Qiita
Copy-on-Write (CoW) — pandas 3.0.1 documentation
What’s new in 3.0.0 (January 21, 2026) — pandas 3.0.1 documentation
Python入門15 DataFrameのgroupbyをマスターする
データサイエンスのためのPython入門15〜DataFrameのgroupbyをマスターする〜 - 米国データサイエンティストのブログ
DataFrameGroupBy.mean()メソッド
pandas 2(2023年)以降、DataFrameGroupBy.mean()メソッドのデフォルト引数がnumeric_only = Falseに変わった。N/Aを含む場合エラーになるので、今回はnumeric_only = Trueの指定が必要。
df.groupby("Pclass").mean(numeric_only=True)
pandas.api.typing.DataFrameGroupBy.mean — pandas 3.0.0 documentation
groupbyの結果をfor文でまわす
客室ランクPclass毎に、Fareでソートしてランキングを割り振るというもの。
results = []
for _, group_df in df.groupby("Pclass"):
sorted_group_df = group_df.sort_values("Fare")
sorted_group_df["RankInPclass"] = np.arange(len(sorted_group_df))
results.append(sorted_group_df)
pd.concat(results)内包表記による方法も試してみた。DataFrame.assign()メソッドでランキングを割り振る。
pd.concat(
[
group_df.sort_values("Fare").assign(RankInPclass=np.arange(len(group_df)))
for _, group_df in df.groupby("Pclass")
]
)途中の変数が減った分、少しは見やすくなったかな?だけど外側のconcat()関数などが相変わらず煩雑に思える。
そこで、Gemini先生に相談したところ、こんな方法が得られた。
results = df.sort_values(['Pclass', 'Fare'])
results['RankInPclass'] = results.groupby('Pclass').cumcount()
resultsDataFrameGroupBy.cumcount()というグループ毎に連番を割り振る関数が適用できるように、sort_values → groupby と順番を逆転することがミソのようだ。こうすることで可読性と処理速度の向上が期待できる。素晴らしい!
pandas.api.typing.DataFrameGroupBy.cumcount — pandas 3.0.0 documentation
matplotlib
matplotlibには従来のMATLAB形式(手続き型)とオブジェクト指向形式の2つの書き方がある。講座は前者から始めて、第21回以降は後者が中心になる。しかし、ところどころMATLAB形式が混在しているので、ここではオブジェクト指向形式の徹底を目指す。
https://github.com/tally1728/usds-notes/blob/main/notebooks/python-20—23-matplotlib.ipynb
Python入門22 matplotlibを使ってグラフをPNG,PDFで保存する
データサイエンスのためのPython入門22〜matplotlibを使ってグラフをPNG,PDFで保存する〜 - 米国データサイエンティストのブログ
プロット同士の重なりを解消するplt.tight_layout()関数は、オブジェクト指向形式ではFigure.tight_layout()メソッドになる。
matplotlib.figure.Figure.tight_layout — Matplotlib 3.10.8 documentation
fig, axes = plt.subplots(2, 1, figsize=(10, 3))
axes[0].set_title("first")
axes[0].set_xlabel("x")
axes[0].set_ylabel("y")
axes[0].plot(x, y1)
axes[1].set_title("second")
axes[1].set_xlabel("x")
axes[1].set_ylabel("y")
axes[1].plot(x, x**2)
plt.show()
fig.tight_layout()
plt.show()
Python入門23 matplotlibで色々なグラフを描画する
データサイエンスのためのPython入門23〜matplotlibで色々なグラフを描画する〜 - 米国データサイエンティストのブログ
| MATLAB形式 | オブジェクト指向形式 | |
|---|---|---|
| 散布図 | plot.scatter()関数 |
Axes.scatter(x, y)メソッド |
| ヒストグラム | plt.hist()関数 |
Axes.hist(x, bins=10)メソッド |
| 箱ひげ図 | plt.boxplot()関数 |
Axes.boxplot(x.dropna()), whis=1.5メソッド |
matplotlib.axes.Axes — Matplotlib 3.10.8 documentation
散布図 Axes.scatter(x, y)メソッド
fig, axes = plt.subplots()
axes.set_xlabel("Age")
axes.set_ylabel("Fare")
axes.scatter(df["Age"], df["Fare"], alpha=0.3)
plt.show()
ヒストグラム Axes.hist(x, bins=10)メソッド
引数binsでヒストグラムの階級数が指定できる。ここで文字列を指定するとnumpy.histogram_bin_edgesでサポートされた階級数の計算法が利用される。
numpy.histogram_bin_edges — NumPy v2.4 Manual
fig, axes = plt.subplots()
axes.hist(df["Age"], bins="auto")
plt.show()
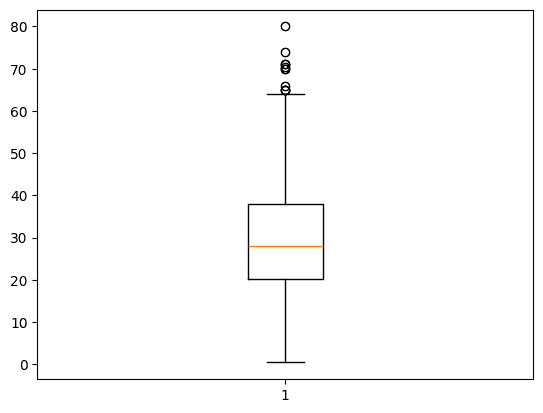
箱ひげ図 Axes.boxplot(x.dropna()), whis=1.5メソッド
fig, axes = plt.subplots()
axes.boxplot(df["Age"].dropna())
plt.show()
Seaborn
matplotlibより高レベルに位置するSeabornでは、関数は figure-level(displot()など)と axes-level(histplot()など)の2種類に大きく分けられる。それぞれでmatplotlibとの関わりが異なる。詳細は第27回で扱う。
Overview of seaborn plotting functions — seaborn https://seaborn.pydata.org/tutorial/function_overview.html
Python入門24 Seabornで簡単にお洒落な図を描画する【ヒストグラム,散布図編】
データサイエンスのためのPython入門24〜Seabornで簡単にお洒落な図を描画する【ヒストグラム,散布図編】〜 - 米国データサイエンティストのブログ
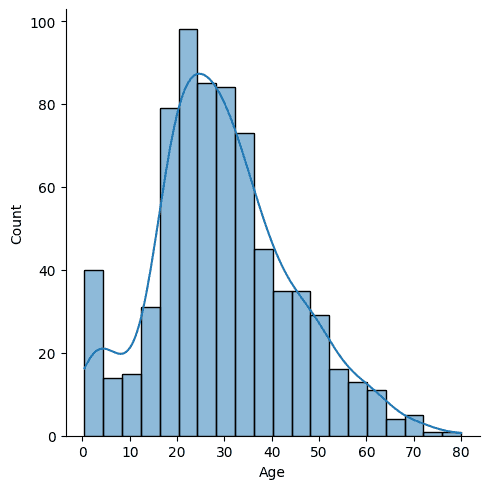
ヒストグラムを描くdistplot()関数は将来削除予定のためdeprecatedとなっている。代わりにfigure-levelのdisplot()関数(多機能)と、axes-levelのhistplot()関数(ヒストグラムに特化の単機能)が奨励されている。
sns.displot(df["Age"], kde=True)
https://seaborn.pydata.org/generated/seaborn.displot.html
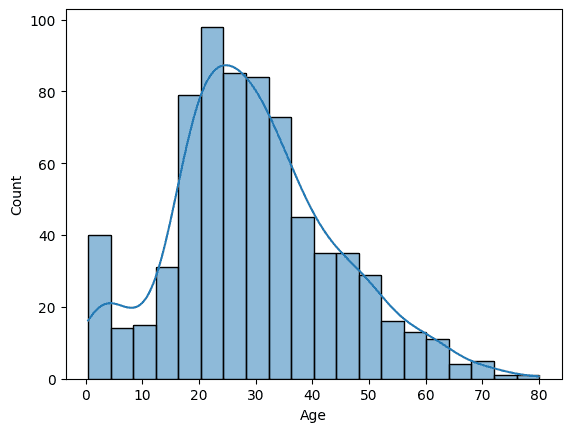
sns.histplot(df["Age"], kde=True)
https://seaborn.pydata.org/generated/seaborn.histplot.html
Python入門25 Seabornで簡単にお洒落な図を描画する【barplot, boxplot, swarmplot等】
データサイエンスのためのPython入門25〜Seabornで簡単にお洒落な図を描画する【barplot, boxplot, swarmplot等】〜 - 米国データサイエンティストのブログ
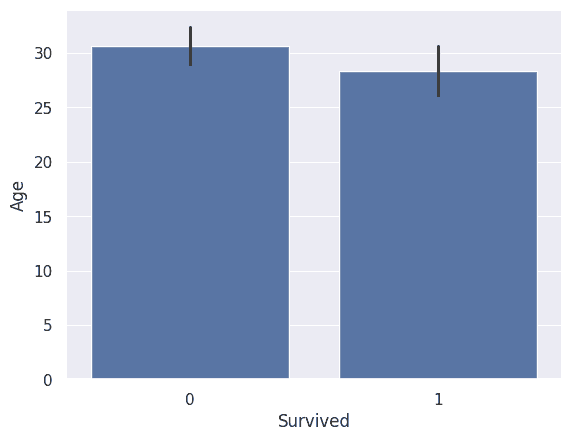
棒グラフを描くbarplot()関数に関して、信頼係数を指定する引数ciはv0.12以降でdeprecatedになり、代わりに引数errorbarが新設された。
sns.barplot(data=df, x="Survived", y="Age", errorbar=("ci", 99))
https://seaborn.pydata.org/generated/seaborn.barplot.html
Python入門27 Seabornの装飾(style)をいじる
データサイエンスのためのPython入門27〜Seabornの装飾(style)をいじる〜 - 米国データサイエンティストのブログ
ビジュアルテーマを設定
ビジュアルテーマを設定するseaborn.set()関数は将来削除予定で、現在はseaborn.set_theme()関数が奨励されている。引数のデフォルト値は次のようになっている。
context='notebook': Scaling parameters →set_context()参照style='darkgrid': Axes style parameters →set_style()参照palette='deep': Color palette →color_palette()参照
https://seaborn.pydata.org/generated/seaborn.set_theme.html
sns.set_theme(context="poster")
sns.histplot(data=df, x="Age", kde=True)
スタイルstyle="ticks"では、横軸と縦軸に目盛りが入る。
sns.set_theme(style="ticks")
sns.histplot(data=df, x="Age", kde=True)
sns.despine()despine()関数で、余分なグラフ上部の横線と右側の縦線が削除できる。ただし、関数の呼び出し順番には注意!despine()はグラフ描画後に呼び出す。
https://seaborn.pydata.org/generated/seaborn.despine.html
matplotlibとの連携
axes-level の関数では、引数axでmatplotlibと関連付けられる。matplotlibの方で、従来通りサイズfigsizeなどが指定できる。
fig, axes = plt.subplots(figsize=(10, 5))
sns.histplot(data=df, x="Age", kde=True, ax=axes)
一方、figure-level の関数では、matplotlibとパラーメータの指定方法が異なる。
サイズは引数height(インチ)と aspect(比率) で指定され、幅はwidth = height * aspectで計算される。
あと、matplotlibのfigsizeのようにFigure全体ではなく、各サブプロットのサイズ である点も異なる。
sns.displot(data=df, x="Age", kde=True, height=3, aspect=2)
また、figure-levelの関数は、FigureクラスよりハイレベルなFacetGridオブジェクトを生成する。例えば、ファイルの保存はFacetGridクラスのsavefig()メソッドが使える。
g = sns.displot(data=df, x="Age", kde=True, aspect=2)
g.savefig("python-27-seaborn_sample.png")https://seaborn.pydata.org/tutorial/function_overview.html
https://seaborn.pydata.org/generated/seaborn.FacetGrid.html
その他
Python入門28〜OpenCVによる画像の読み込みと色空間の変換,表示
データサイエンスのためのPython入門28〜OpenCVによる画像の読み込みと色空間の変換,表示〜 - 米国データサイエンティストのブログ
opencv-pythonパッケージではなく、GUIを含まないopencv-python-headlessパッケージであれば、libsm6などのライブラリを追加せずに利用できる。
https://github.com/opencv/opencv-python https://pypi.org/project/opencv-python-headless/
Python入門31 osモジュールとpathlibモジュールを使って安全にPath操作をする
データサイエンスのためのPython入門31〜osモジュールとpathlibモジュールを使って安全にPath操作をする〜 - 米国データサイエンティストのブログ
後半はosモジュールを用いているが、大抵の処理は高レベルなpathlibモジュールでも実現できる。
osモジュール |
pathlib.Pathクラス |
|---|---|
path.split()関数 |
parent, name, partsプロパティ |
path.join()関数 |
joinpath()メソッド, /演算子 |
path.exists()関数 |
exists()メソッド |
makedirs()関数 |
mkdir()メソッド |
https://docs.python.org/ja/3/library/pathlib.html
パスの分割
>>> p_abs
PosixPath('/app/notebooks')
>>> p_abs.parent
PosixPath('/app')
>>> p_abs.name
'notebooks'
>>> p_abs.parts
('/', 'app', 'notebooks')パスの結合
>>> p_abs.joinpath("test.txt")
PosixPath('/app/notebooks/test.txt')
>>> p_abs / "test.txt"
PosixPath('/app/notebooks/test.txt')パスの存在確認とディレクトリの作成
new_dir = p / "python-31-new-dir"
if not new_file.exists():
new_dir.mkdir()Python入門32 これだけ知っておけばいいmultiprocessingでの並列処理
データサイエンスのためのPython入門32〜これだけ知っておけばいいmultiprocessingでの並列処理〜 - 米国データサイエンティストのブログ
PNGファイルを大量に用意するのが大変だったので、代わりに大きな乱数配列を生成してソートする CPUバウンド な重い処理(sort()関数)を例とした。
# CPUバウンドな重い処理を実行する関数
# 大きな乱数配列を生成してソートする
#
# 引数
# seed: 乱数のシード
# length: 配列の長さ
# n_iter: 処理の反復回数
def sort(seed, length=1_000_000, n_iter=100):
rng = np.random.default_rng(seed)
for _ in range(n_iter):
random_array = rng.integers(0, high=length, size=length)
random_array.sort()
# print("Sorted a random array by seed: {}".format(seed))
return TrueJupyterLab での並列処理
講座を同様にp.map()関数で並列処理しようとすると、
p = Pool(processes=cpu_num)
params = range(100)
try:
p.map(sort, params)
finally:
p.close()
p.join()AttributeError: module '__main__' has no attribute 'sort'というエラーで動かない。
原因を調べたところ、近頃のPythonの仕様変更とJupyterLabの仕組みに起因していることが分かった。Python 3.14以降で、子プロセスはfork(高速・非安全)でなく forkserver(forkとspawnの間の子) で開始するようになった。一方、JupyterLabのセルに書かれた関数は、メインのプロセス(メモリ上)には存在するが、物理的な .py ファイルには書き込まれていない。そのため、新しいプロセスがsort 関数を読み込もうとメインプログラム(main)を見に行っても、ファイルの実体がないのでsort()関数を見つけることができない。
https://docs.python.org/ja/3/library/multiprocessing.html
というわけで、並列処理で実行したい関数を外部ファイル(tasks.pyなど)に切り出せば解決する。併せて%autoreload(第33回を参照)を使うと良い。
もう一つ重要なのは、メインモジュールの安全なインポートを実現するためのおまじないif __name__ == "__main__":だ。これにより、p.map()を実行するのはメインに限定され、子プロセスが更なる並列処理を無限に開始する恐れが予防できる。
https://docs.python.org/ja/3/library/multiprocessing.html#the-spawn-and-forkserver-start-methods
import my_tasks
if __name__ == "__main__":
p = Pool(processes=cpu_num)
try:
p.map(my_tasks.sort, params)
finally:
p.close()
p.join()補足だが、定番のwithだと、実行後にゾンビプロセスが残ってしまう。明示的にclose(), join()するのが吉。
Pool.imap()メソッドとPool.imap_unordered()メソッド
map()の遅延評価版であるPool.imap()メソッドに対して、イテレーターが返す結果の順番が重要でない場合はPool.imap_unordered()メソッドも使える。
https://docs.python.org/ja/3/library/multiprocessing.html#multiprocessing.pool.Pool.imap_unordered
複数の引数を関数に渡す場合
データサイエンスのためのPython入門⑤〜文法まとめ2 関数〜 - 米国データサイエンティストのブログ の*argsは 関数定義 におけるアンパックの説明だった。
一方、p.map()から呼ばれるラッパー関数wrap_sort()の実装における*argsは、関数呼び出し の方での用例となっている。
def wrap_sort(args):
return sort(*args)*演算子は「リストやタプルなどを展開(アンパック)する」という作用があり、例えばargs=(0, 1000000, 100)という引数でwrap_sort(args)関数が呼ばれた場合、*によりタプルの()が展開され、sort(0, 1000000, 100)がコールされる。